
As organizations become more data-driven, they have moved data ownership from a central data team into the hands of those who best understand how given datasets can best support their objectives: the various functions and departments spread across the whole organization. This has led to distributed data management best practices, such as Data Mesh, to become more popular.
In short, Data Mesh is a best practice for how individual functions can take ownership of their respective data, including its sources, structure, ongoing governance, and make it available to others as a “Data Product.” The role of the central data team changes from data ownership to being an enabler and facilitator of this best practice, including providing and maintaining data platforms and data management tools, and being available as a “center of excellence,” offering education and guidance to the various functions.
Snowflake offers many features to help organizations implement Data Meshes. It is designed to be a distributed data platform, with both operational and analytical workloads being distributed and owned by individual teams, and supporting both real-time and batch data movement and sharing. It provides several ways of instantiating Data Products, ranging from distinct schemas within a database to distinct accounts spread across many clouds and regions, and publishing them via Snowflake’s Data Marketplace. With Snowflake, Data Product Owners can easily take ownership of implementing and publishing their Data Products, at scale.
But with ownership comes important responsibilities. One that in our experience is often overlooked is data security. In the rush to get Data Mesh principles rolled out and Data Products stood up to start serving the needs of the organization, data security is often regarded as something the Data Product Owners will manage on their own, or treated as a subsequent “we will get to it later” activity. Both are mistakes. While Snowflake offers native access controls, dynamic masking and other security features that allow Data Product Owners to manage data security within their own Snowflake instances and schemas, additional capabilities are needed to ensure a solid and well-governed data security foundation across the entire Data Mesh. In this blog, we’ll explain why, and offer practical guidance to get started with Data Mesh securely, without sacrificing speed and agility.
Your Data is Broadly Distributed Across a Data Mesh. What Could Possibly Go Wrong and How to Get it Right?
To get security right and avoid nasty surprises after Data Products have already been implemented and shared, it’s important to design security in from the very beginning. Specifically, one should consider the following security issues:
1. How to define and manage access controls when sensitive data is distributed across many Data Products?
Many of your organization’s Data Products may include sensitive data. This is especially true for customer-facing functions, who must often use personally identifying information (PII) and other regulated data to properly serve those customers. Moreover, Data Products can be composable: Data from one team’s Data Product may be used as part of another team’s, and so on, creating a daisy-chain of data being shared across your organization. This can happen especially with “master” datasets, e.g., one team owns the golden records for customers, which then get picked up by every team that needs at least some customer data. Data Mesh principles support maintaining such copies of the data by design and Snowflake makes it ever more easier with modern data sharing concepts like Zero Copy Clone.
However, regulations such as GDPR require that controls are consistently applied wherever such data appears. If each team is left on their own to define access control policies (or fail to do so entirely), it will be “wild west,” with blind spots, compliance violations, and breaches and fines just waiting to happen. It is critical to define fine-grained access controls centrally, and to deploy and enforce them in all the Data Products that data may appear. While Snowflake offers native controls, these work only within individual Snowflake databases, and not across multiple databases that may appear across multiple Snowflake accounts, regions, and clouds.
TrustLogix is complementary to Snowflake’s native access controls by offering centralized visibility and control of sensitive data, across all databases, accounts, regions and clouds that data may appear. Thus you can have a single point of defining and ensuring policies are applied consistently across all your Data Products.
2. How do you get visibility to your overall data security posture across all the Data Products in your Data Mesh?
Regulations such as GDPR require that controls are consistently applied, and require that you can prove this. Having each Data Product Owner decide on their own how to monitor and report on their data security posture won’t solve for this. It is critical to have a single point of visibility—a single dashboard—for data access across all your Data Products.
TrustLogix offers centralized visibility, including alerts and reporting on issues as they arise, thus providing you with a single holistic view of your data security posture. This also serves as evidence to regulators that you have adequate controls of your sensitive data across your entire organization.
3. How do you deal with ever-growing numbers of roles across the organization?
Each Data Product will usually come with its own new set of roles and attributes, for that Data Product’s intended users. If similar data is being used across many Data Products, and Data Product Owners are left on their own to define and manage their roles, then “role explosion” is the likely outcome, with convoluted and overlapping roles that can be assigned to many users for each Data Product they are allowed to consume. This will lead to operational chaos, as users end up with more or less access than expected, as well as security risks due to over-privileged accounts. It’s critical to have a central view of roles to ensure this doesn’t happen.
TrustLogix solves for this by providing a single view of your role hierarchy across your entire organization, so you can strike the right balance between simplicity and giving various users access to the data they need (no more and no less).
4. How do you respond quickly to data access requests from Data Products’ users?
Ultimately Data Product Owners are responsible for enabling their Data Products’ intended users to be successful with their data, as well as ensuring access policies are met. Ideally this should be possible without access approval processes being the bottleneck, thus negating the Data Mesh’s original promise of agility and self-service. It is critical to ensure fast policy provisioning in response to data access requests, in a manner that each Product Data Owner can do themselves without violating organization-wide policies and best practices.
TrustLogix solves for this with a visual no-code approach to defining policies, including recommendation of policies based on templatized best practices. These templates are defined and managed in one place, typically by the central data team on consultation with the Security and Privacy experts for the various regulations. Data Product Owners can simply apply these templates to their Data Products, confidently and without guesswork.
Additionally, TrustLogix’s Access Analyzer enables rapid troubleshooting of access issues. If a user says they aren’t able to access certain data and they should be able to, Access Analyzer shows that roles and policies apply to that user, and which one(s) are blocking access, so the Data Product Owner can quickly resolve and get their users back on track.
5. How to alert on and remediate new data security risks across the entire organization?
Data is always changing, and how the organization is using that data is always changing. Additionally, data users come and go (due to turnover, transfers and so on). For example, it is easy to forget to turn off a terminated employee’s privileges, and it is easy to forget to remove an outdated dataset that is no longer being used. Keeping access controls up-to-date is critical. TrustLogix offers a single point of visibility to alert on such issues, as well as recommending appropriate remediations which one can then implement at the click of a button.
TrustLogix continuously monitors for such situations, and raises alerts as well as recommended resolutions in a central console so that both Data Product Owners and Security owners can review and resolve quickly and easily.
Persistent Systems’ Approach to Ensuring a Secure Data Mesh
As enterprises transition from a Data Lake or Data Warehouse implementation to the Data Mesh, it is important to understand the main building blocks of Data Mesh:
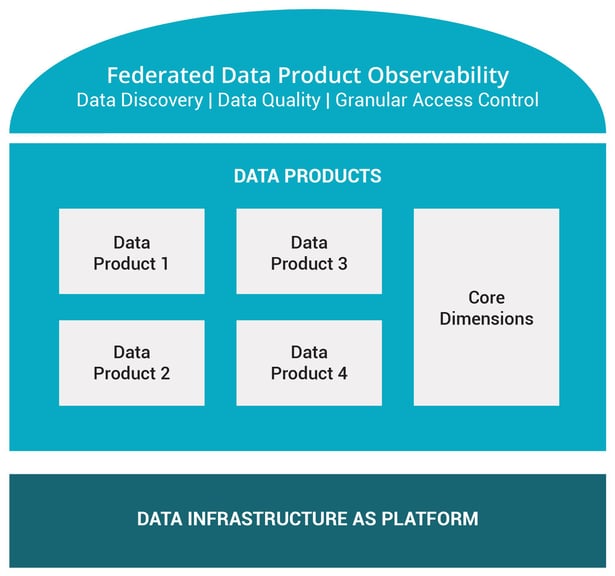
- Data Platform
- Data Products prepared and maintained for each Data Domain
- Central Data Observability Layer
At Persistent Systems, we have helped our customers adopt to Data Mesh by
- Creating a Data Mesh Ready Platform built on top of Snowflake
- Decomposing the existing Data Warehouse or Data Lake implementation to Domain driven Data Products
- Implementing a modern Data Observability Layer, which should include (1) data discovery and classification, (2) data quality, and (3) access control capabilities that can operate at scale across all Data Products.
The decomposition of Data Warehouse into multiple Data Products is both art and science. This can be a complex undertaking for organizations that have not segmented their data in this manner before, and hence often gets the highest attention. However, the central Data Observability layer is the most important pillar, and is often ignored until the lack thereof presents the organization with the following challenges:
- Without Data Discovery and Classification, the Data Products cannot be easily searched and hence will often be ignored by all except those consumers who had prior knowledge if the respective Domains’ existence.
- The consumer of the Data Products needs (contractual) guarantees on schema, freshness and quality metrics of the Data Product which are exposed by the Data Quality Framework, without which they cannot easily determine if the Data Product can be trusted for their business needs.
- And finally, without granular access control tooling, it becomes very difficult to correctly grant access to the right consumers. In a typical medium size implementation, enterprises will have 100+ Data Products managed by 35+ Data Product Managers who are part of Domain or Business Teams. Making them learn the complexities of RBAC, IAM, Secured Views, and Masking Policies is too complicated. It also means CSOs will have to chase those product managers to get any security audit reports. Having a tool like TrustLogix monitoring the Access Control at the top solves these issues.
In conclusion, Data Mesh has been adopted by many enterprises to become more data-driven at scale, by putting Data Product ownership in the hands of the people who know the data best: the various functions and departments distributed across the organization. But without putting a proper foundation in place, Data Product owners are then left on their own to implement data access control and observability on their own, leading to “wild west” operational chaos and greater risk of data security breaches and compliance failures. Persistent Systems has extensive experience in helping organizations implement successful and scalable Data Meshes that focuses on laying the foundation first, including leveraging TrustLogix to ensure data security and access control is well-managed from the beginning.