
Data is being created today at speed and scale that we’ve never seen before. Spurred on by the promise of digital transformation, much of this data is being natively created or published out to cloud data platforms like Snowflake, Redshift, and Databricks. Unfortunately, broad swaths of this data is then left ungoverned, leading to data breaches that expose organizations’ most sensitive assets.
.png?width=872&name=Birth%20Certificate%20(blank).png)
Fortunately for CISOs, CDOs, and data owners and stewards, solutions already exist that empower you to govern data as it’s being created. Taking this data-centric security approach is the best way to ensure that you’re securing your data “as it’s born”.
The Data Creation Challenge
Traditionally, as new systems were being rolled out, they would go through a Security Review or Governance cycle where Identity & Access Management (IAM) fundamentals would be applied to ensure that only the appropriate people would have access to the systems and information to which they were entitled.
Today, as organizations move to massive cloud-based data platforms like Snowflake, Redshift, and Databricks, the old model no longer holds.
- People are granted access to systems, not data – there is little to no governance in place to control which data a particular user or role should be allowed to access
- The volume of data that is being generated is unprecedented – Data is being created and moved across heterogeneous platforms that the Data Governance team is unable to keep their arms around – In addition to Snowflake and others, data consumers are pulling data to Tableau and Qlik, or writing their own Python scripts to analyze new information.
- The breakneck speed at which data is being generated leaves incumbent data governance processes unable to keep up with the required governance
Read: Why IAM is Insufficient for Data-Centric Security
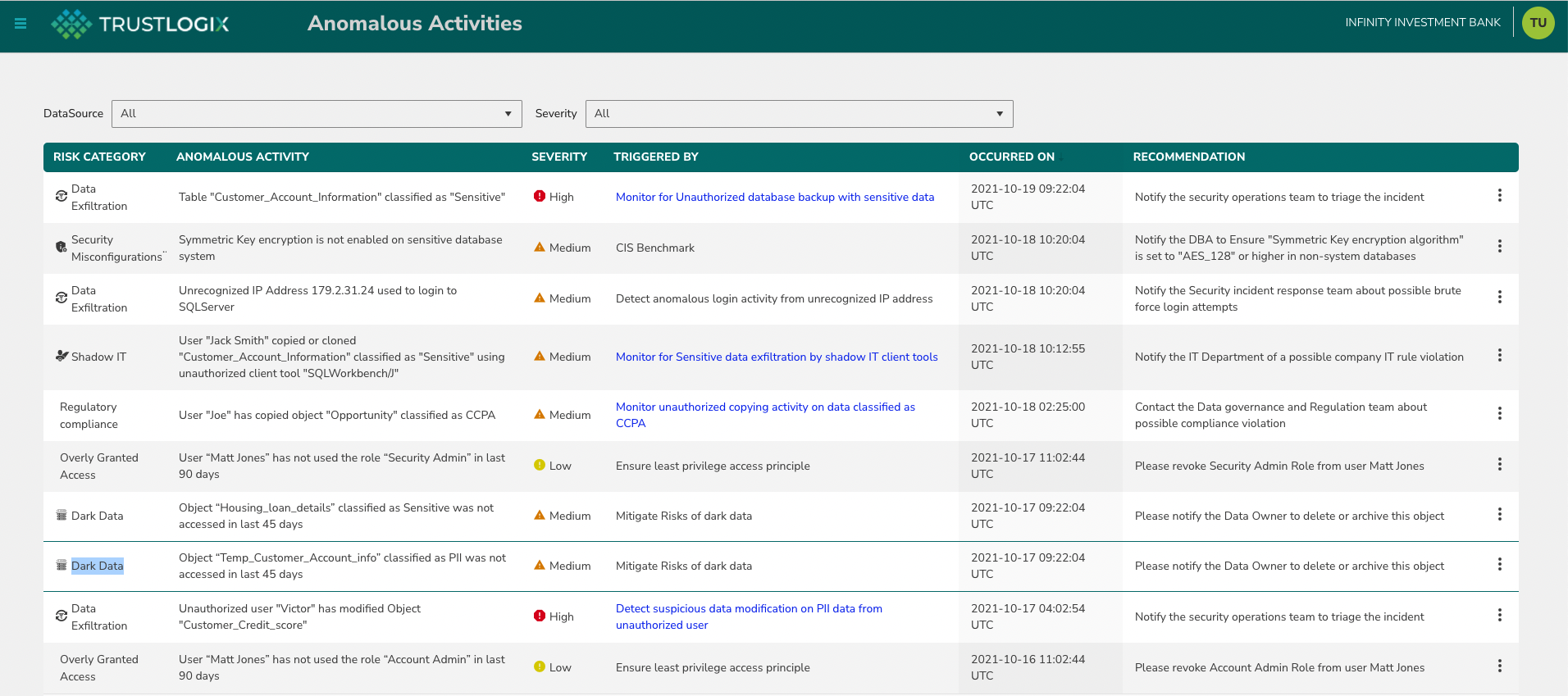
Challenges – Dark and Ungoverned Data
These new dynamics lead to challenges that we’re facing for the first time as an industry. How do we allow the business to move forward at the pace and scale that is needed while still protecting ourselves from leaving that data inadequately protected. Our current approaches leave us exposed along a number of dimensions.
- Dark Data – Data gets generated in anticipation of use, and never actually gets consumed by anyone. This creates a high-risk / low-reward exposure surface that has only downside for the business.
- Ungoverned Data – These are datasets that get created / migrated to the cloud and left completely unprotected. Trust us, this happens all the time.
- Stale Entitlements – This was data that was either generated or granted-access-to on the fly for a specific initiative. The initiative is complete, but the data is still accessible.
- Compliance violations -- Due to failing audits for SOX, HIPAA, GDPR, CCPA, and other legislative mandates
Read: 7 out of the top 10 Data Breaches of 2021 were in the cloud
Solution Part 1: Data Classification
The first part of tackling this problem is by leveraging Data Classification engines. There are a myriad of solutions available that you can point to every single one of your cloud data sources to automatically classify the data within as PII, PCI, HIPAA, etc.
Bottom line: You can’t actually have data access control if you don’t know where your sensitive data resides, and exactly how sensitive it is. Select a tool and point it to your data sources (with resource cycles built in for curation) to automatically classify your data as it’s born. Even without any other controls in place, it will give you visibility into where you have data risk exposure.
You should come away with a clear sense of:
- This is PHI data (HIPAA)
- This is PII data (GDPR)
- This is Credit Card information (PCI)
- This *could* be SOX-relevant
Read: Collibra and TrustLogix Close the Loop Between Data Classification and Data Access
Solution Part 2: Data Access Control
There are numerous ways to apply granular data access control policies for your sensitive information. Each cloud data platform (Snowflake, Redshift, Databricks, etc.) provides rich native constructs that allow you to define which users or roles should have access to what data. Leverage these native tools to define granular controls over how users can access your data.
Leverage these capabilities in conjunction with the learnings from your data classification engine(s) to model and enforce data access control policies that can incorporate classification tags to more tightly control how your sensitive data is accessed.
Takeaways:
- This column in Snowflake contains Credit Card information, make sure that it’s masked for all people that aren’t in Finance
- This Redshift dataset has been flagged as HIPAA data, so only clinicians should have access to it, and only if the rows match up to people for whom they are on the Caregiver list.
Read: Data Lake Security: An Explanatory Guide with Best Practices
Data Access Governance: Secure Your Data at “Birth”
Here’s where the magic can happen. You can put these two critical pieces together to protect your data as it is being created, as part of a holistic data centric security strategy. You can now model policies that apply to all data across all platforms without prior knowledge of the contents of the data being created.
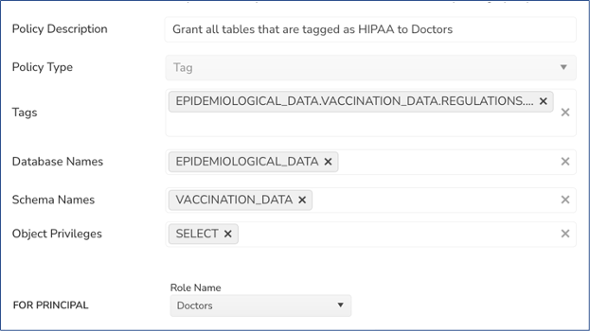
Data Access Governance platforms empower you to leverage Classification tags to define overarching policies that will immediately enforce existing policies on new data, based on the sensitivity of that data.
You can use a Data Access Governance platform to define policies like:
- All Credit Card data must be masked for all authorized users except Finance across all data platforms
- All PII data is inaccessible to all users except those on the explicit Allow list
- Any Clinical data is only available to designated Caregivers
Read: A Four-Step Framework for Data Centric Security
Benefits & Conclusion
This approach has an immediate and positive impact on the data creation → classification → security → consumption lifecycle.
- Data Stewards and Data Owners can define governance principles at a business level, and pass them off to their security counterparts
- Data Security professionals can then model those policies in your Data Access Governance Platform once and have confidence that they will be correctly enforced across all platforms and for all existing and future datasets
- Most importantly, data consumers have instant access to new datasets, and that access is completely governed by your pre-defined policies
The pace and scale of data creation is only going to increase. Overburdened security organizations are already struggling to stay abreast of delivering visibility and granular controls for governing who should have access to that data. A data centric security approach will help you pre-define business-level policies about how your data should be protected, and ensure that it is cohesively and universally applied to all your data, as it’s being born and regardless of where it resides.
